Fulfillment and Assurance cannot continue to be independent processes and stacks.
There, I said it.
For as long as any of us can remember, fulfillment and assurance were two independent processes, mostly because they were conceived, operated and purchased by separate departments. As Alfred D. Chandler demonstrated in his classic book “Strategy and Structure”, operations and even business structure follow organizational charts and vice-versa. Fulfillment and assurance are no exceptions, with those organizations driving processes and supporting software purchases. While many know that its not ideal, the situation has mostly worked.
As I covered in my last blog, virtualized networks promise some incredible agility and opex cost reductions, along with other significant benefits. But (big but!), these gains demand highly efficient, hands-off automation. One of the things we learn from control theory – which is one branch of engineering associated closely with real-world automation, is that there must be a single control method – and what we think of as “assurance” is simply an input (feedback) into that method. One method, not two, nor three.
Actually, feedback loops are beautiful things (especially if you’re a nerd). They are simple. Designed properly, they tend to converge, which means they are self-correcting. And, with a single method (loop), there’s effectively no “systems integration”, because there are not two independent systems.
Let’s also think about the practicality of fulfillment, especially in tomorrow’s world where a packet core, or a data-center full of NFV-I must be shared among hundreds of services and 10,000s of customers. In the old days, we found a free loop, or trunk and “assigned” it to you. Done. Now, we have to figure out where there is sufficient spare capacity, on a statistical basis, to support your needs 99.99% of the time, or whatever the SLA or product requirement says. This is an assurance function, and it precedes the completion of an order. Let’s put that another way, assurance is a contributing function to a successful order. Not only SHOULD assurance and fulfillment not be separated, they CANNOT be.
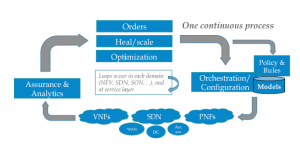
All this goes back to the idea of one orchestration method that supports both Fulfillment and Assurance. In effect, active assurance becomes a “re-fulfillment” effort – working around, for example, the failure of [underlying] box “X”. The job of assurance is to a) detect that box X failed, figure out what services are affected, and trigger a remediation effort on the part of orchestration, complete with all the new data (e.g.: “don’t go putting these services back on Box X”).
In the end we still have a Fulfillment process, a Assurance process, and a capacity expansion process. But for many reasons, these should share many common components, such as common orchestration methods, common Active Inventory, and common live topology. This leaves next-generation assurance to migrate to what it does best – collect data, correlate events, and turn all this underlying data into intelligence. In effect assurance (and Analytics) become the “brains” driving myriad decision from smart fulfillment, to self-healing to self-scaling (capacity expansion) – and other actions outside the scope of this blog.
I encourage you to read much more about it in the recently published Research Note, “Closed Loop Automation and the New Role of Assurance”, available here:
https://appledoreresearch.com/report/closed-loop-automation-new-role-assurance-research-note/
… and to read Appledore Research available individually or under subscription, from Appledore Research.
“Managing The Telco Cloud”, ARG 2015.
“The Role of Policy in Virtualized Networks”, ARG 2015.
“The Economics of Virtualized Networks”, ARG 2016.
“The Role of Closed-Loop Automation in Virtualized Networks”, ARG 2016.
“Service Assurance in Hybrid Virtualized Networks”, ARG 2016.
Finally, look for our upcoming webinar done in partnership with a major supplier of this technology who will also share their practical experience.